
I’ve had a recurring thought, following by some intense Googling — using this Hugo powered site to microblog. The idea has been fueled by two desires; owning my own “microblogging” data — and making it quicker, and easier, to post something on my own domain.
Being able to quickly snap a photo with my phone and publish it is not so easy with a static website. So I got the idea of using the Todoist app, and their API to post, build, and publish.
This is the story of how I did it, and why it wasn’t a good idea.
Table of contents
Why?
It’s been almost a year since I last published something on this blog… I’ve been thinking about it, I just never had took the time to sit down and actually do it.
I do tweet post project updates to Twitter X (such a weird name 🤷). Anyway — I’ve often wished it was easier to post those updates directly to my own blog, instead of some social media.
As one often does; I set out do make an elaborate solution to use Todoist tasks as data source for my own microblog implementation. You know — instead of writing.
Implementation
todoist-microblog
├── post.py
├── run.sh
└── todoist.py
Python
First off; I needed to pull data from the Todoist API. They have a Python SDK, but it felt excessive for my use case. Instead I made my own:
import requests
import json
api_headers = { "Authorization": "Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" }
def get_tasks() -> dict:
r = requests.get(
"https://api.todoist.com/rest/v2/tasks?filter=%23Micro blog %26 (today|overdue)",
headers=api_headers
)
return r.json()
def get_comments(task_id: str) -> dict:
r = requests.get(
"https://api.todoist.com/rest/v2/comments?task_id=" + task_id,
headers=api_headers
)
return r.json()
def delete_task(task_id: str):
r = requests.delete(
"https://api.todoist.com/rest/v2/tasks/" + task_id,
headers=api_headers
)
def close_task(task_id: str):
r = requests.post(
"https://api.todoist.com/rest/v2/tasks/" + task_id + "/close",
headers=api_headers
)
def download_file(url: str, file_name: str):
r = requests.get(url,
headers=api_headers,
allow_redirects=True
)
open(file_name, 'wb').write(r.content)
To get tasks I used a filter that returned open tasks in the “Micro blog” project, due today or overdue:
#Micro blog & (today|overdue)
Since attachments in Todoist can only be used with comments, I also needed to pull comments for the tasks. Putting all of this together I ended up with the following Python script, it imports and uses the Python module above:
import requests
import json
import os
import shutil
from datetime import datetime
from dateutil import tz
from dataclasses import dataclass
import todoist
@dataclass
class Task:
task_id: str
title: str
text: str
datetime: str
labels: list
parent_id: str
@dataclass
class Attachment:
file_name: str
file_type: str
file_url: str
resource_type: str
upload_state: str
def convert_timezone(str_time: str) -> (str, str):
from_zone = tz.tzutc()
to_zone = tz.tzlocal()
utc_time = datetime.strptime(str_time, "%Y-%m-%dT%H:%M:%S.%fZ")
local_time = utc_time.replace(tzinfo=from_zone).astimezone(to_zone)
post_time = local_time.strftime("%H%M%S")
return local_time, post_time
if __name__ == "__main__":
for task in todoist.get_tasks():
print(task["id"])
print(task["content"])
print(task["description"])
print(task["created_at"])
print(task["labels"])
print(task["parent_id"])
attachments = []
for i, comment in enumerate(todoist.get_comments(task["id"])):
print(comment)
print("%02d" % i)
if comment["attachment"] is None:
continue
print(comment["content"])
print(comment["attachment"]["file_name"])
print(comment["attachment"]["file_type"])
print(comment["attachment"]["file_url"])
print(comment["attachment"]["resource_type"])
print(comment["attachment"]["upload_state"])
if comment["attachment"]["resource_type"] != "image":
print("Only images are supported as attachments")
continue
file_name = "img" + ("%02d" % i) + "_" + comment["attachment"]["file_name"].lower()
todoist.download_file(comment["attachment"]["image"], file_name)
attachments.append(file_name)
local_time, post_time = convert_timezone(task["created_at"])
markdown = []
markdown.append("+++\n")
if task["description"] != "":
post_slug = task["content"].lower().replace(" ","-")
markdown.append("slug = \"" + post_slug + "\"\n")
if task["parent_id"] is not None:
markdown.append("threads = [\"" + task["parent_id"] + "\"]\n")
if task["labels"]:
markdown.append("hashtags = [" + ', '.join(f'"{w}"' for w in task["labels"]) + "]\n")
markdown.append("date = \"" + local_time.isoformat() + "\"\n")
markdown.append("author = \"Thomas\"\n")
markdown.append("+++\n")
markdown.append("\n")
if task["description"] != "":
markdown.append(task["description"] + "\n")
else:
markdown.append(task["content"] + "\n")
if len(attachments) == 1:
markdown.append("\n")
markdown.append("{{< figure src=\"" + attachments[0] + "\" >}}\n")
elif len(attachments) > 1:
markdown.append("\n")
markdown.append("{{< carousel src-match=\"img*.jpg\" >}}\n")
with open("index.md", "w") as myfile:
myfile.writelines(markdown)
post_path = f"micro/{local_time.strftime('%Y/%m/%d')}/{post_time}"
os.makedirs(post_path)
shutil.move("index.md", post_path)
for attachment in attachments:
shutil.move(attachment, post_path)
todoist.close_task(task["id"])
Not the prettiest of scripts, but it got the work done… Here is a breakdown of the logic flow — for all tasks returned with the filter above:
- Get all comments
- If comment has no attachments: skip it
- If comment has image attachment: download image as
imgXX_filenameXXstarting at 00 and incremented by one
- Create a new markdown file
- Use task title as post slug and task description as post content
- If task has no description: the title becomes the content
- If task is subtask: use parent task ID as thread ID
- If task has labels: use as hashtags
- Use task created time as post published date
- If task has single image: insert
figureshortcode - If task has multiple images: insert
carouselshortcode - Save to
micro/%Y/%m/%d/%H%M%S/index.md
- Use task title as post slug and task description as post content
- Move downloaded images into the post folder
- Close task in Todoist
Shell
The Python script above was executed from a Bash script — which also did a few other things:
#!/bin/bash
cd /home/thomas/dev/todoist
python3 post.py
subdircount=$(find micro/ -maxdepth 1 -type d | wc -l)
if [[ "$subdircount" -ne 1 ]]; then
find micro/ -name "*.jpg" -exec img-r2.sh 1600 {} \;
for img in $(find micro/ -name "img00*.jpg"); do
target_folder="$(dirname "${img}")"
convert $img -resize "800x600^" -gravity center -crop 800x600+0+0 -strip $target_folder/post-thumbnail.jpg
done
rsync -avh micro/* sigma:dev/cavelab-blog/content/micro/
#rm -r micro/*
#cd ~/dev/cavelab-blog; git add content/micro; git commit -m 'add micropost'; git push
#ssh build 'cd cavelab-blog; make deploy_dev'
fi
- Get Todoist data and create post using Python script
post.py - If tasks were available and processed (content was created)
- Auto rotate and resize all images (
*.jpg) - Create
post-thumbnail.jpgfrom the first image (img00*.jpg) - Sync content in
micro/to computersigma - Commit to git and trigger website build?
- Auto rotate and resize all images (
I never finished the last point — I abandoned the approach before it got to “production”.
This is the script I use for auto rotating and resizing images:
#!/bin/bash
for file in "${@:2}"
do
exiftran -ai "$file"
convert "$file" -resize $1x$1\> "$file"
done
Hugo
A few changes was necessary in Hugo; first — the new permalinks and taxonomies had to be defined:
[permalinks]
micro = "/:year/:month/:day/:slugorfile"
[taxonomies]
thread = "threads"
hashtag = "hashtags"
In the single page template; I added hash tags and threads:
{{- if .Params.hashtags -}}
<span class="post-tags">
{{- range .GetTerms "hashtags" -}}
<a class="p-category" href="{{ .Permalink }}"><span class="p-category-hash">#</span>{{ .LinkTitle }}</a>
{{- end -}}
</span>
{{- end -}}
{{- with (.GetTerms "threads") -}}
<div class="post-series-bottom">
<p>This micropost is part of a <a href="{{ (index . 0).Permalink }}">thread</a>.</p>
</div>
{{- end -}}
I created a new list template for microposts:
{{ define "main" }}
<div class="index-content {{ if .Params.framed -}}framed{{- else -}}bottom-border{{- end -}}">
<h2>
{{ .Title }}
{{- with .OutputFormats.Get "rss" }}
<a href="{{ .Permalink }}">{{ partialCached "feed-icon.html" . }}</a>
{{- end -}}
</h2>
{{ .Content }}
</div>
<div class="posts">
{{ range $k, $v := .Paginator.Pages.ByDate }}
<div class="post on-list">
<div class="post-content" style="font-size:1.2em">
{{- with .Content -}}
{{ . }}
{{- end -}}
</div>
{{- if .Date | default nil -}}
{{- $pubDate := .Date.Format ($.Site.Params.DateFormat | default "2006-01-02") -}}
<span class="post-date">
<time class="dt-published" datetime="{{- .Date.Format "2006-01-02T15:04:05Z0700" -}}">
<a class="read-more button" href="{{ .RelPermalink }}">{{- $pubDate }} →</a>
</time>
</span>
{{- end -}}
</div>
{{ end }}
{{ partial "pagination.html" . }}
</div>
{{ end }}
The biggest changes being:
- No post title
- Show posts chronologically
- Use font size 1.2em
- Include all post content, not just summary
- Use date as permalink to post, below content
Changes may also be required to the RSS template, but I never got that far…
Examples
With a Todoist task like this:
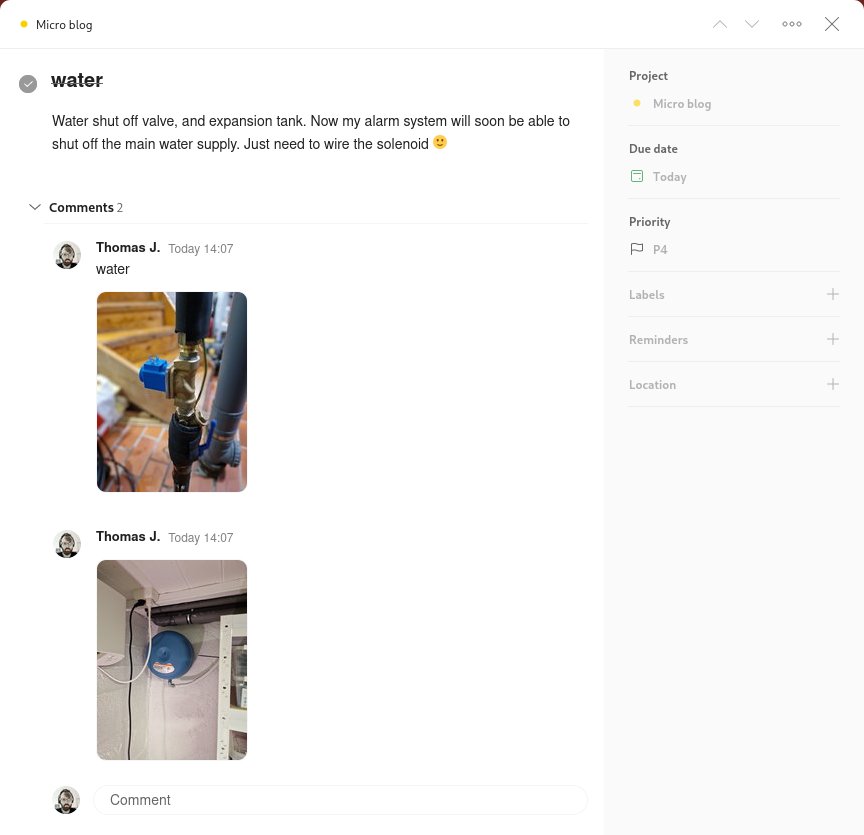
The created micropost content looked like this:
+++
slug = "water"
date = "2023-11-10T18:15:32.263523+01:00"
author = "Thomas"
+++
Water shut off valve, and expansion tank. Now my alarm system will soon be able
to shut off the main water supply. Just need to wire the solenoid 🙂
{{< carousel src-match="img*.jpg" >}}
And the micropost list page looked like this, note the image carousel:

With sub tasks and labels in Todoist:
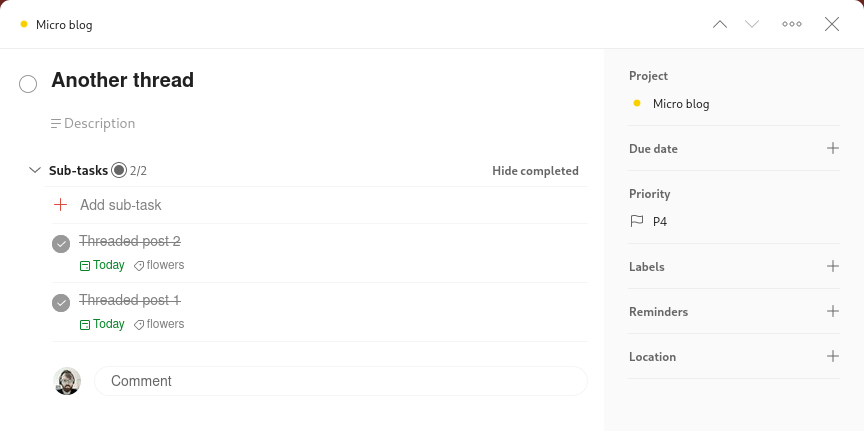
All sub tasks got created as microposts, using the main task ID as threads taxonomy:
+++
threads = ["7404503408"]
hashtags = ["flowers"]
date = "2023-11-12T18:49:43.313273+01:00"
author = "Thomas"
+++
Threaded post 1
{{< figure src="img00_dsc_3380.jpg" >}}
A single page, or micropost, with a single image, hashtag and part of a thread:

Why not?
After all that tinkering — I still didn’t use any of it… Why?
Although it was a cool technical solution; it wasn’t a great solution overall — for a few reasons:
- It was even easier to produce short and low effort content. What I really want to write is blog posts, some long, some short — but blog posts. The right solution is to stop procrastinating and take time to write proper posts.
- It made my blog a hell of a lot more complex, using external APIs, scripted post creation, and triggered builds. That’s a lot of moving parts… I like it simple 🙂
- The number of pages, and potentially images, on this site would increase a lot. Each micropost with its own page. That is a lot of low quality pages…
- By using some social media platform for project updates — I’m increasing the audience. Creating interest for the blog post that “closes” the projects and sums everything up.
Afterword
I wasn’t really sure if this post was worth writing. Since I didn’t use any of it, and actually reverted all the Hugo changes before documenting it properly.
But I do think it was a cool solution, even though I didn’t end up using it. Maybe someone else will find it useful 🤓
And — it felt good to actually write again, I’m set on doing more of that ✍️
Last commit 2024-11-11, with message: Add lots of tags to posts.
